Digital Audio Primer For Subliminal Mixing
By awixas January 12, 2020
What is sound?
The sound we hear is our brain's interpretation of tiny vibrations in air pressure. For example, if you hit a drum, then the air molecules above the drum skin are pushed, which in turn pushes the air molecules next to those and so on. The air compression propegates outwards in the form of a wave of high and low pressure so that when it reaches your ears, the pressure fluctuations vibrate your tympanic membrane (ear drum) in your ear. You could represent these air pressure waves on a graph where one axis is time, and the other is pressure:
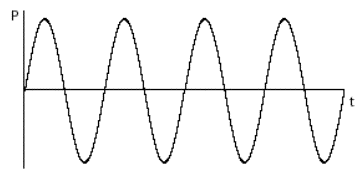
When the wave reaches your ear, and your tympanic membrane begins to vibrate at the frequency of the air wave, and your nerves send this as a signal to your brain. The result is the remarkable experience of hearing sounds. From an evolutionary point of view, we evolved to be able to hear so that we could detect dangers, find resources like water, communicate (even non-verbal before language was created) and to be able to understand our suroundings. This is why we are wired to have emotional reactions to the sounds we hear. We are compelled in different ways by different sounds. For example, the sound of a babbling brook is relaxing because our the DNA of our anscestors has programmed us to realize that we are safe and have water when we hear it. On the other hand, the sound of a snake hissing or a wild animal growling will trigger a danger alert and cause us anxiety or fear.
How audio works in speakers and microphones
Speakers create sounds by vibrating the air with a membrain or diaphram (think of the big circles that look a bit like satelite dishes that you see on the front speakers) that is attached to a strong magnet. The magnet in turn is situated near an electromagnet, which can be manipulated to attract or repel by sending it electrical pulses. The electromagnet is attached to an input signal that dictates when to attract and when to repel. The magnet then pushes and pulls the membrain to produce the fluctuation in air pressure. This is done really fast to create tiny vibrations in the air that we could hear as sound.
Microphones, in simple terms, use the same principle as speakers, only in reverse. So instead of a signal vibrating the membrain, it's the air pressure vibrations that push and pull the magnet attached to the membrain. As a result the magnet moves and those movements could be captured as a digital or analog signal.
Difference between digital and analog audio
When we talk about analog signals, we are referring to a continuous signal that represents physical messurements of a wave. It is a smooth signal like a sine wave and captures all the information of the original sound source. However, when we want to capture this smooth wave information into a computer readable file, it needs to be converted to ones and zeros because computers can only store information in binary. A digital sound file, like .wav files, are discrete chunks of data that represent the sound wave only at a finite set of positions. Audio files are usually sampled at a high rate so that there are tens of thousands of of data points per second to store the sound wave data, but it will always be an aproximation of the original smooth wave signal. Does that sound a bit complicated? This image should show you the difference clearly:
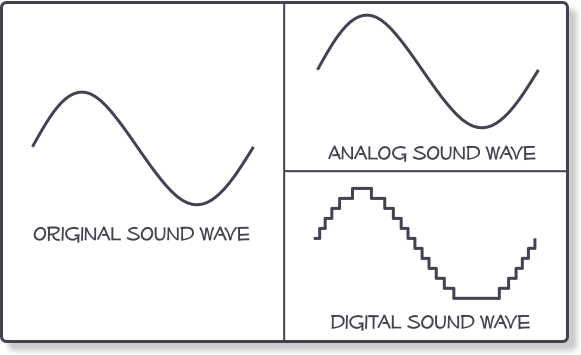
Sample Rate
In audio signal processing, sampling is the the reduction of a continuous time signal to a discrete time signal - analog to digital. A sample rate is the number of 'samples' of audio per second stored in a digital audio file. The higher the sample rate, the closer you can get to the original smooth wave information, but you can never get the original wave data perfectly. Sample rate is usually expressed in Hz, which stands for Hertz and means "cycles per second." So 1 Hz is equal to one sample per second. Most audio files have a sample rate of tens of thousands samples per second like 44100 Hz, 48000 Hz, 96000 Hz. That's a lot of data every second!
Compression
As we learned from understanding sample rate, the amount of data needed to store a digital audio file could be huge when the sample rate is high. In order to reduce the file size, computer scientists have created algorithms that can greatly reduce the filesize of audio information. This is using codecs by removing information redundancy, using pattern recognition, encoding and decoding as well as other tricks.
There are two categories of data compression for reducing audio file size: Lossy and Lossless. As the names imply, lossy reduces file size by removing certain parts of the sound wave information. Lossy audio compression uses psychoacoustics to determine what data can be discarded. For example, Lossy file reduction will remove parts of a digital sound wave that are above and below the threshold of human perception. This type of compression will remove some types of subliminal messages that are embedded at those frequencies.
Important To Understand For Making Subliminal Mixes:
You will lose your subliminal embeds if you don't understand compression!
FROM WIKIPEDIA: https://en.wikipedia.org/wiki/Data_compression#Audio
"The innovation of lossy audio compression was to use psychoacoustics to recognize that not all data in an audio stream can be perceived by the human auditory system. Most lossy compression reduces perceptual redundancy by first identifying perceptually irrelevant sounds, that is, sounds that are very hard to hear. Typical examples include high frequencies or sounds that occur at the same time as louder sounds. Those sounds are coded with decreased accuracy or not at all."
*Note: This does not mean that you can't have a good subliminal in a lossy format, only that when creating, converting or downloading subliminal mixes you need to be aware of data loss effects on subliminal embeds.
On the other hand, lossless compression algorithms generally do not lose any information of the original digial wave data. So a lossless compression is reversable because no data is lost. Lossless compression uses data redundancy and encoding.
Dynamic compression
People often confuse Compression with Dynamic Compression. The difference is really simple. Dynamic compression is more related to music production rather than to reducing file size. Dynamic Compression is a proccess where the volume of loud sounds is lowered and the volume of low sounds is raised. This is often done in music production to reduce a signals dynamic range so that some sounds could pop out more, or a sample could be amplified without clipping.
Formats:
lossless:- wav
- aiff
- flac
- alac
- mp3
- aac
- oog
Citations and Acknowledgements
- https://en.wikipedia.org/wiki/Dynamic_range_compression
- https://en.wikipedia.org/wiki/Audio_signal
- https://music.tutsplus.com/tutorials/the-beginners-guide-to-compression--audio-953
- https://en.wikipedia.org/wiki/Audio_codec
- https://manual.audacityteam.org/man/compressor.html
- https://www.blackghostaudio.com/blog/the-ultimate-guide-to-compression
- https://www.howtogeek.com/142174/what-lossless-file-formats-are-why-you-shouldnt-convert-lossy-to-lossless/
Special thanks to reddit user /u/sovereignsubliminals for encouraging me to continue this project
© 2020 subliminizers.com All Rights Reserved